
Spis treści
Wiele stron nie ma ustawionych właściwie tagów kanonicznych, co – zwłaszcza w przypadku sklepów – prowadzi do dużych problemów związanych z indeksowaniem produktów (i innych treści, jak blogowe artykuły), co przekłada się na niski ruch na stronie, a co za tym idzie i małą ilość klientów. Warto zadbać więc o porządek, wdrażając właściwą politykę korzystania z tagów kanonicznych (rel=canonical).
Dlaczego używamy podobnych stron
Aby obsłużyć wiele typów urządzeń
https://example.com/news/url
https://m.example.com/news/url
https://amp.example.com/news/url
Aby nie indeksować parametrów czy identyfikatorów sesji
https://www.example.com/produkt?kategoria=sukienki&kolor=zielony
https://example.com/sukienki/mini?gclid=ABCD
Gdy blog generuje różne adresy url dla tego samego artykułu, znajdującego się w różnych kategoriach
https://blog.example.com/search-console/tag-kanoniczny/
https://blog.example.com/optymalizacja-stron/tag-kanoniczny/
Jeśli treści umieszczone na blogu w celu redystrybucji w innych witrynach są w nich powielane częściowo lub w całości:
https://news.example.com/google-update.html (post po redystrybucji)
https://blog.example.com/google/core-update-sierpien-2024/3245/ (oryginalny post)
Jeśli serwer jest tak skonfigurowany, aby wyświetlać te same treści na stronach www i innych niż www, http i https oraz korzystających z różnych odmian portu protokołu:
https://example.com/zielone-sukiernki
https://example.com/zielone-sukiernki
https://www.example.com/zielone-sukiernki
https://example.com:80/zielone-sukiernki
https://example.com:443/zielone-sukiernki
Jak określić tag kanoniczny
rel=canonical
Najlepszym rozwiązaniem jest jednak użycie wskazanego w artykule zapisu rel=canonical. Należy pamiętać tylko wtedy, że ta metoda działa tylko w przypadku stron HTML i nie działa w przypadku plików, np. PDF. Możesz wtedy użyć jednak nagłówka HTTP rel=canonical.
Nagłówek HTTP rel=canonical
Nie zwiększa, jak w/w metoda, rozmiaru strony, jednak nie sprawdzi się w dużych stronach oraz tam, gdzie urle zmieniają się bardzo często.
Jest jeszcze kilka mniej popularnych metod, które Google opisuje na swojej stronie – znajdziesz tam także więcej wskazówek dotyczących omówionych dwóch metod.
Dlaczego warto wybrać adres kanoniczny
Rel=canonical ułatwia bardzo życie, ponieważ pozwala decydować (próbować) o tym, co powinno być zaindeksowane w wynikach wyszukiwania, a co powinno istnieć tylko dla wygody osób, które odwiedzają naszą stronę.
Tag kanoniczny pozwala łączyć sygnały, jakie płyną z odnośników (innych linków) – jeżeli mamy 5 stron i do każdej z nich kieruje po jednym linku, to dzięki rel-canonical wszystkie 4 (ze stron, które posiadają rel-canonical do strony głównej) zostanie połączone z linkiem, który prowadzi do strony wskazanej w rel-canonical.
Najważniejsze jest też to, że dbasz o to, aby Google nie indeksował niepotrzebnych adresów, zachowując je jednocześnie dla użytkowników, którzy odwiedzają Twoją stronę. Dzięki temu Google skupia się tylko na indeksowaniu nowych stron (oraz zmian na starych stronach), a nie na indeksowaniu różnych wyglądów (wersje na komputery i komórki)
Polecam oglądnięcie poniższego filmu, na którym pracownik Google podaje kilka dodatkowych kwestii związanych z rel=canonical, na które warto zwrócić uwagę:
Co wpływa na wybór tagu kanonicznego
Informację o tym, jaki tag wybrać, Google czerpie z różnych źróde:
- wskazania w sekcji head strony – rel=canonical
- jakość strony
- obecność adresu url w sitemapie (mapie witryny)
Bardzo ważne tutaj jest to, że możemy wskazać Google, np. poprzez etykietę, co chcemy, aby zostało wybrane jako tag kanoniczny przez Googlebota, ale to robot indeksujący, na podstawie swojego algorytmu, podejmuje decyzję o tym, jaki tag kanoniczny wybrać.
Złe podejście?
Niekoniecznie.
Wyobraź sonbie sytuację, gdzie ustawiasz (lub webmaster) przez pomyłkę tag kanoniczny na KAŻDEJ stronie swojej witryny, który kieruje do strony głównej.
Oznacza to, ze oczekujesz od Googlebota, aby wyindeksował wszystkie strony poza stroną główną (wskazałeś ją jako kanoniczną). To podręcznikowa sytuacja, w której Google bot uzna, że się pomyliłeś i nie wyindeksuje podstron.
Inna sytuacja to zmiana z http na https – adresy url mają już https, ale webmaster zapomniał o zmianie rel=canonical, który nadal ma http. W tej sytuacji Google także uzna, że się pomyliłeś i będzie indeksować w przeważającej większości strony z https. Znam przykład sklepu, który działał tak przez lata, notując wysokie pozycje w wynikach wyszukiwania pod ule zawierające https – mimo, że tag kanoniczny wskazywał na http.
Zobacz, co mówi o tym John z Google
Jak sprawdzić, jaki adres Google wybrał jako kanoniczny
Używamy do tego Search Console – wprowadzamy adres url na górze ekranu
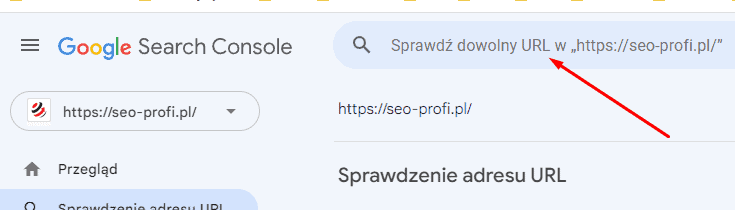
a następnie, jak Google zakończy test, rozwijamy sekcję
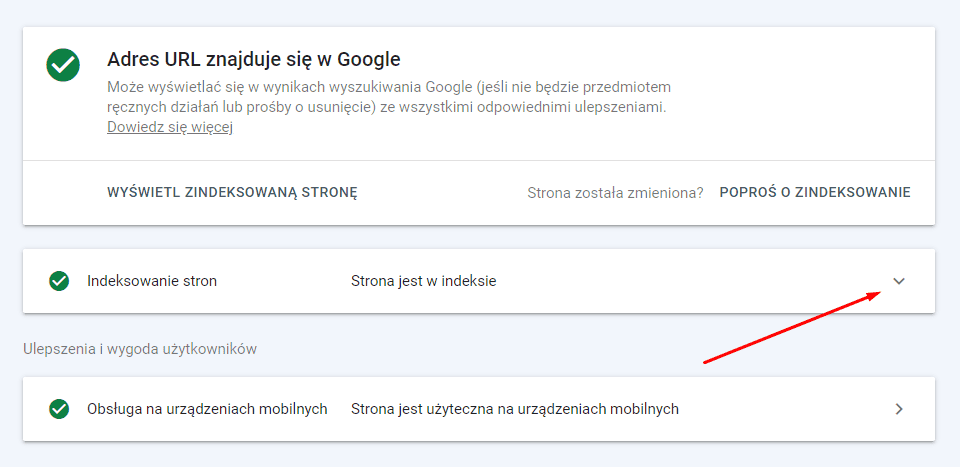
i sprawdzamy sekcję indeksowanie – jeżeli Google wybrało tag kanoniczny, który określiliśmy, powinniśmy zobaczyć taki komunikat
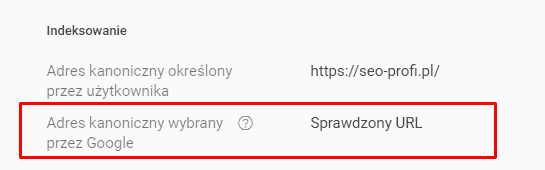
Pamiętaj, o czym pisałem wcześniej – Google może wybrać inną stronę z różnych powodów, na przykład ze względu na jej treść lub wydajność. Jeżeli zatem wybrany adres jest inny niż oczekiwany, musisz się tym zająć.
Duplikaty w wynikach wyszukiwania
Google może wyświetlić w wynikach wyszukiwania duplikat, jeżeli uzna, że będzie to lepszy wynik niż wskazana strona kanoniczna. Na przykład jeśli użytkownik korzysta z komórki, w wynikach wyszukiwania najprawdopodobniej pojawi się strona mobilna – nawet gdy jako kanoniczna została wskazana strona na komputery.
Wersje językowe
Należy podkreślić, że tagu kanonicznego używamy tylko w obrębie tej samej wersji językowej.